浏览器事件模型
缺陷
1.说起浏览器的原生的事件模型,首先印入脑海的是onclick,onload等事件,然后才是addEventListener,removeEventListener,确实在平常的编码过程中接触到更多的是封装过的on,off之流。
2.在日常处理click等事件之时,会使用到阻止冒泡(event.stopPropagation),阻止默认行为(event.preventDefault)或者直接reture false,但却没有真正去深入了解事件的传递机制。
发现
今天阅读的时获取了很多新知识,在此作记录
首先是html
1 | <!DOCTYPE html> |
大概就这样
然后添加事件,从window,document,html,body,parent,child依次添加捕获与冒泡事件的监听,并打印出事件的目标节点和当前节点。
1 | <script> |
点击蓝色的p标签,控制台信息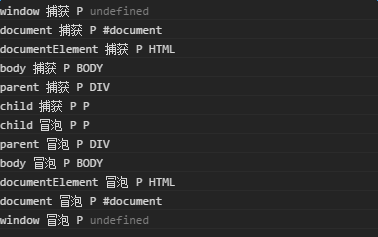
是真的先捕获再冒泡吗?还是因为事件绑定的顺序?
交换捕获和冒泡的绑定顺序之后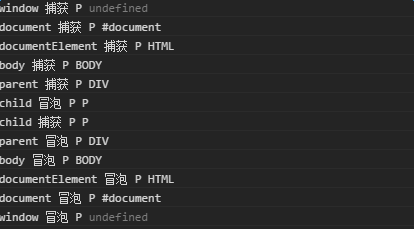
出现child的捕获冒泡顺序发生变化,原来这就是目标阶段了,当target与currentTarget相等之时就进入目标阶段,这时候绑定的事件是按绑定顺序依次触发的,所以在child上写的”捕获”,”冒泡”应该都改为”捕获”才对。
再做个验证:在所有事件绑定之前,添加
1 | child.onclick = function(){ |
点击得到以下结果: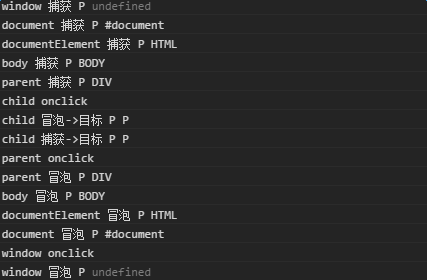
总结
1.事件的捕获是从上至下触发了window,document,documentElement, body,parent绑定的事件。
2.当来到child节点时,是目标阶段,事件按照绑定顺序依次触发。
3.冒泡阶段与捕获阶段相反,自下而上的传递,而一些onclick之类的事件也都在该阶段触发,但是为啥在这个阶段呢?看下一条。
4.IE的事件流中只存在冒泡这个阶段,所以为了跟好地兼容IE。。。至于那个只有捕获阶段的网景,有个了解就好。
5.到这里,标准的浏览器事件已经梳理地差不多了,可能在平时编码过程中的影响不是很大,对它的实现原理的了解不是多多益善吗?